Problem
You are a product manager (scrum term: product owner) for a software and you have to decide based on effort and business value which feature to implement next. This blog post will ellaborate on a highly sophisticaded solution for the problem of effort estimation.
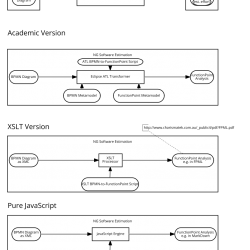
Standards
When using scrum the user requirements are captured as user stories. In my opinion user stories do not have enough information to build good software based on them and they can’t be used to train other users on the software.
We recommend to use BPMN diagrams for describing the business process that the user is doing. By definition they create value.
For software effort estimation there are multiple ways. I would guess the most common ways are expert estimations. In our experience if there is no project plan or other things to derive them from these expert estimations are most of the time around the factor 2-3 lower than expected.
A better way to do software estimations is Function Point Analysis. Function point is purely based on the business requirements and can give a quite good estimate how “big” a software module is. To get to a good overall cost and time estimate the functions points should be used as an input for COCOMO.
Example
We will use the following BPMN diagram as an example:
This diagram is a process for managing todos items. An implementation of this application can be found here. It is published on github.
Analysing BPMN
As you can see there are currently four user tasks, one service task, a data store, gateways, two swimlanes and multiple events (start, stop, throw message and catch message). For us only the user tasks and the data store is interesting. The reason for this is, that we are only interested in logic recognizable by the user.
| Type | Label |
|---|---|
| Activities | |
| UserTask | Overview todos |
| UserTask | Create todo |
| UserTask | Update todo |
| UserTask | Delete todo |
| Data objects | |
| DataStore | Todo |
Mapping BPMN elements to Function Point elements
For function point counting only the visible business logic for the user is important. So we mostly care about the activities that are shown in the user swimlane.
We have to map the BPMN elements to Function Point elements. Here is a list of our rules:
- Every data store is an ILF (Internal Logic File)
- Every user task is an elementary process
- If there is an outgoing message it is an EI (External Input)
- If there is an incoming message where the sending activity is labeled “Send.*” it is an EQ (External Inquiry)
- Otherwise it is an (External Output)
- Every collapsed pool that receives a message is an EIF (external interface file)
So this gives us the following table:
| BPMN Element | BPMN Label | Rule | Function Point Element |
|---|---|---|---|
| UserTask | Overview todos | 2.2 | EQ |
| UserTask | Create todo | 2.1 | EI |
| UserTask | Update todo | 2.1 | EI |
| UserTask | Delete todo | 2.1 | EI |
| DataStore | Todo | 1 | ILF |
This already worked quite well.
Estimating complexity of elementary processes
The easy way to estimate the complexity of the elementary processes would just be to use “Rapid Approximation” which means to give every transaction a level of “average” and every data store with the complexity “low”.
So what do we get:
| Label | Function Point Element | Complexity | Function Points |
|---|---|---|---|
| Overview todos | EQ | average | 4 |
| Create todo | EI | average | 4 |
| Update todo | EI | average | 4 |
| Delete todo | EI | average | 4 |
| Todo | ILF | low | 7 |
| Sum | 23 | ||
Lets do this more sophisticated. For every elementary process also referred as transactions we now need the amount of file type references (FTR) and the data element types (DET). Again we need a list of rules how to translate BPMN concepts to function analysis concepts.
- For external inquiries the amount of data outputs is counted as DETs
- For external inputs the amount of data inputs is counted as DETs
- The amount of FTRs is conducted by using the path in the system process from start to end that goes through the message by identifying all data stores that are referenced
Ideally we already have for every user task a wireframes and based on this wireframe we can do our counting.
We get the following:
| Label | Function Point Element | Amount of DETs | Amount of FTR or RET (Record Element Types) | Complexity | Function Points |
|---|---|---|---|---|---|
| Overview todos | EQ | 1 | 1 | low | 3 |
| Create todo | EI | 1 | 1 | low | 3 |
| Update todo | EI | 1 | 1 | low | 3 |
| Delete todo | EI | 1 | 1 | low | 3 |
| Todo | ILF | 1 | 0 | low | 7 |
| Sum | 19 | ||||
Conclusion
Is this blog posted we showed an highly automizable way to go from a BPMN diagram to a solid effort estimation in function points. BPMN and Function Point Analysis are both industry standards that are well proven in practice and it is easy to find documentation, training material and educated people.
Based on a COCOMO Calculator the given process would take 1.89 month to implement. The basis for this analysis can be downloaded here: Basic-COCOMO-Model
Leave a Reply