This blog post will show an example for the parallel query processing capabilities from PostGIS 2.3 running on PostgeSQL 9.6. It is based on the project Lebensriskoexplorer.
The data that I am using are exported from my google location history from 2015.
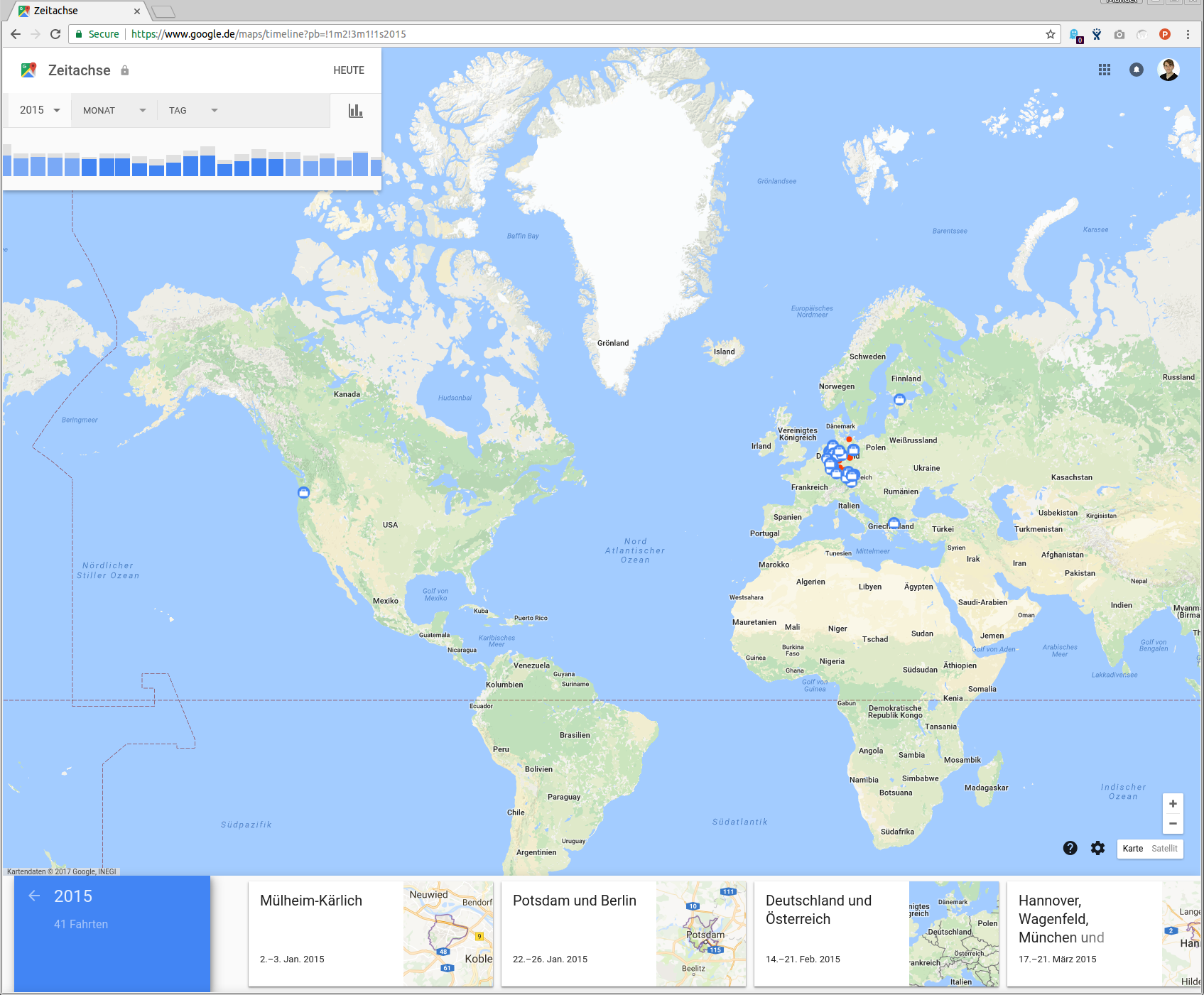
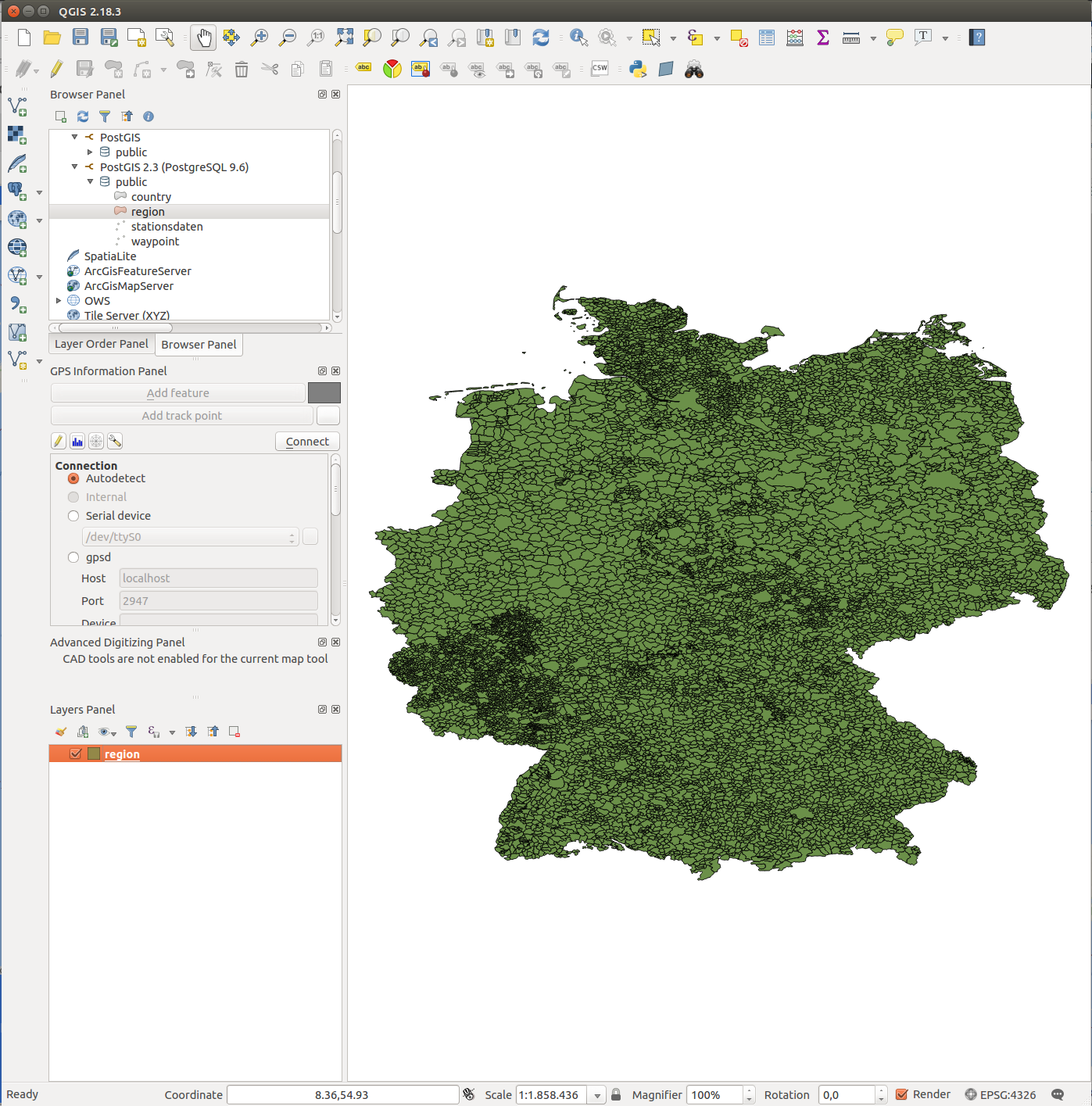
The region data is taken from the Bundesamt für Kartographie und Geodäsie.
So overall we have the following amount of data:
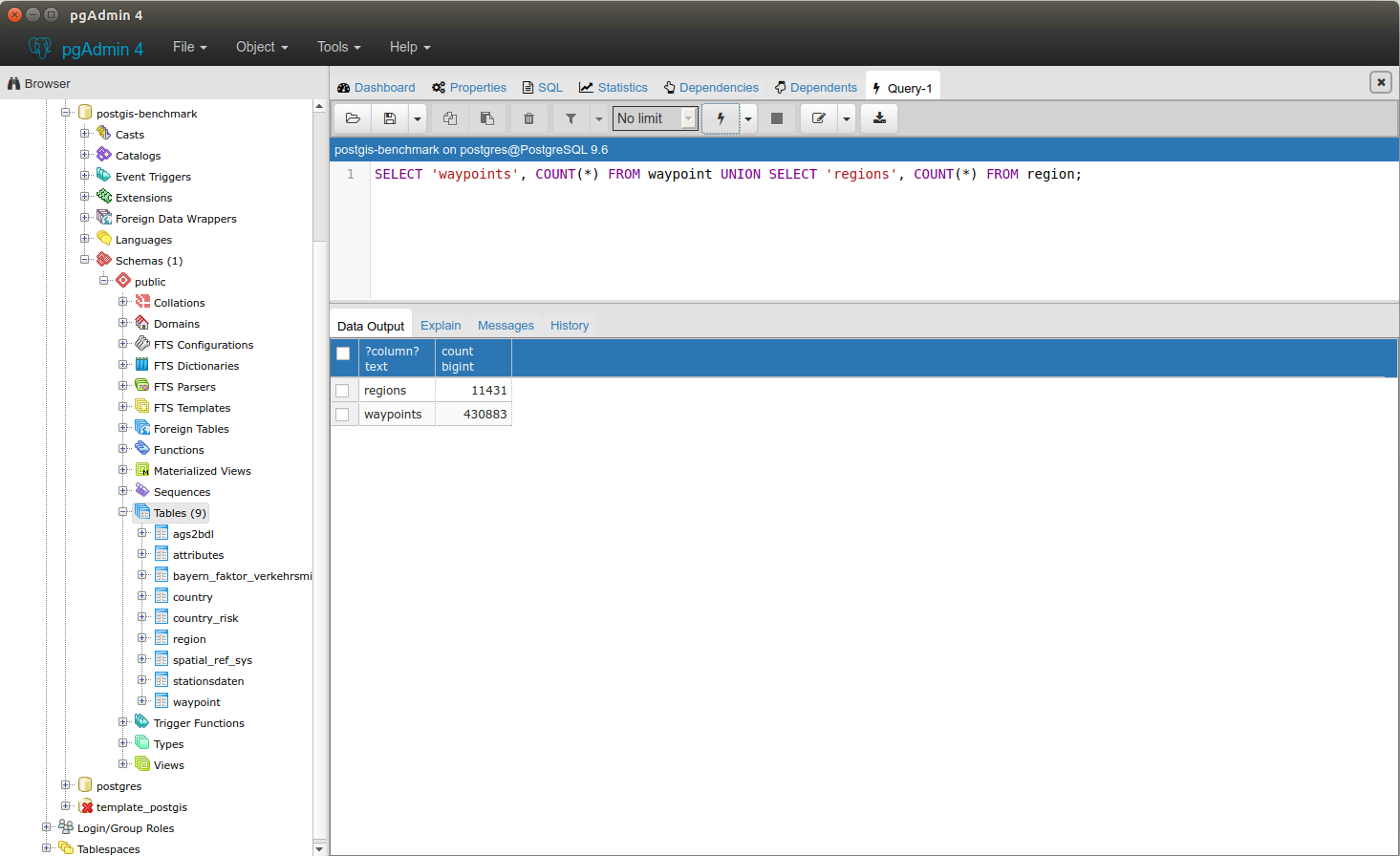
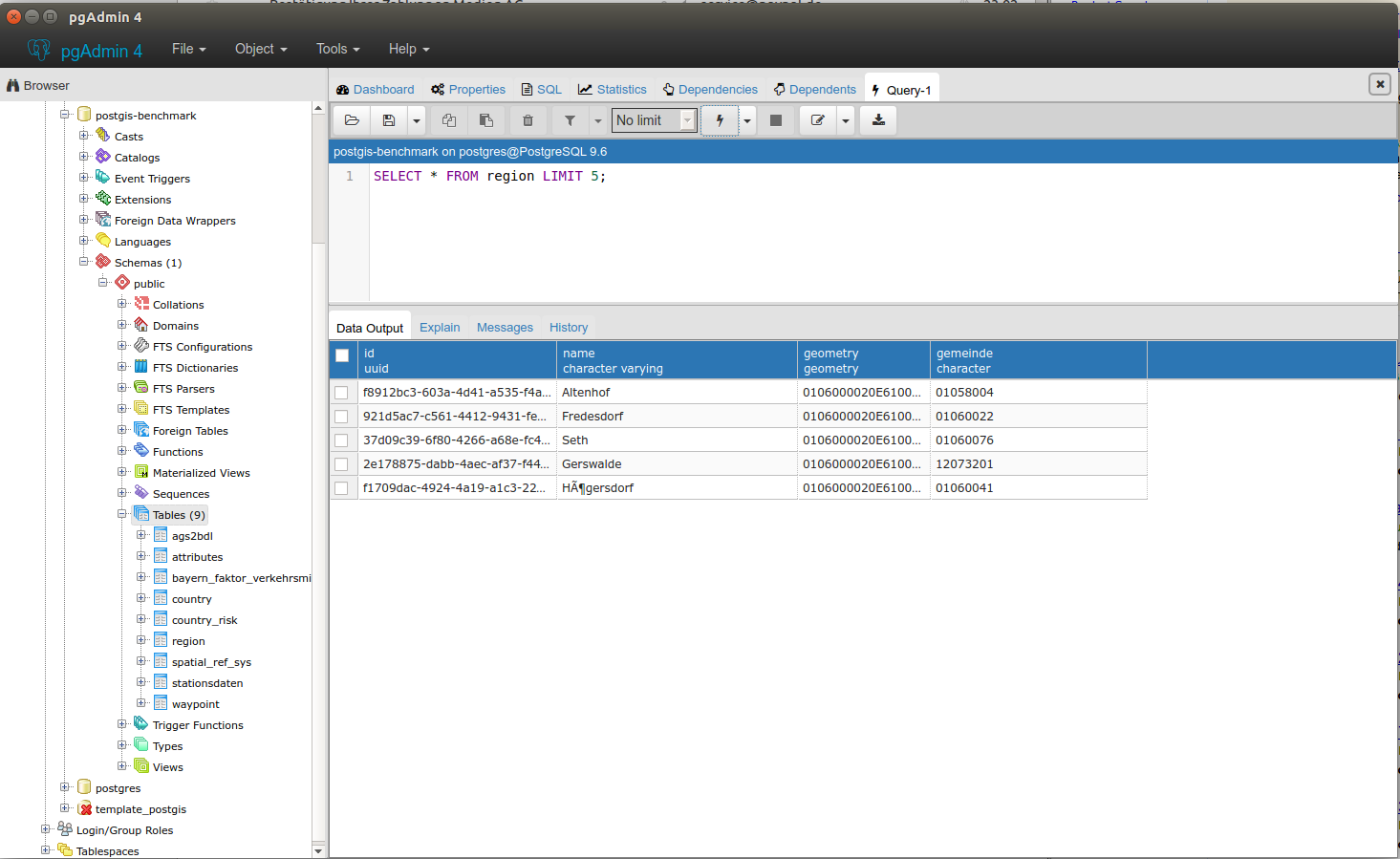
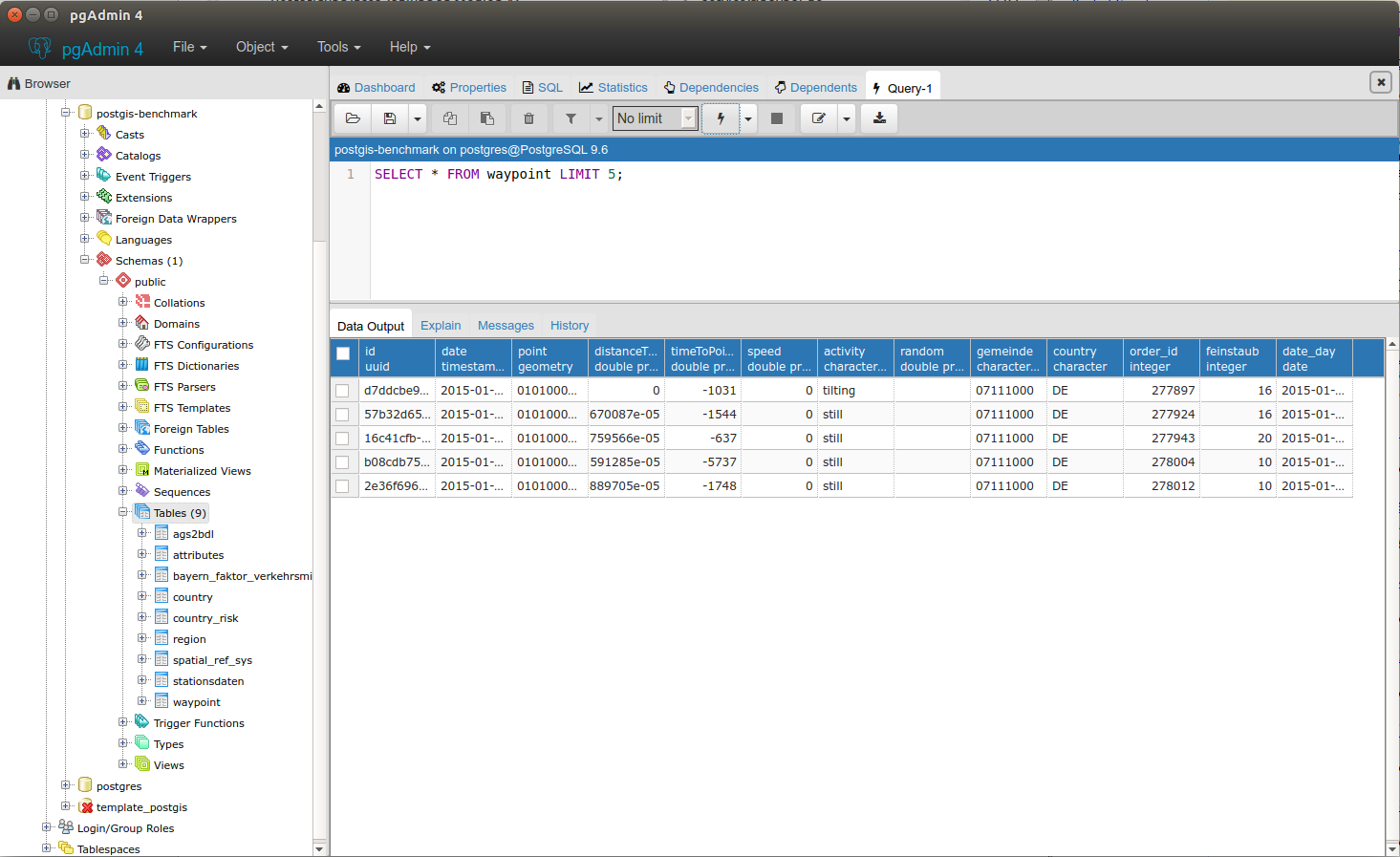
| Name | Amount |
|---|---|
| Waypoints | 430,883 |
| Regions | 11,431 |
So the question is now which waypoint is in which region and how many points are in this region:
SELECT r.name, COUNT(*) FROM region r, waypoint w where ST_WITHIN(w.point,r.geometry) GROUP BY r.name
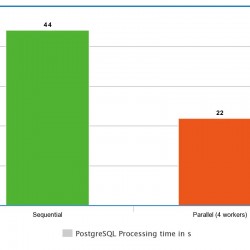
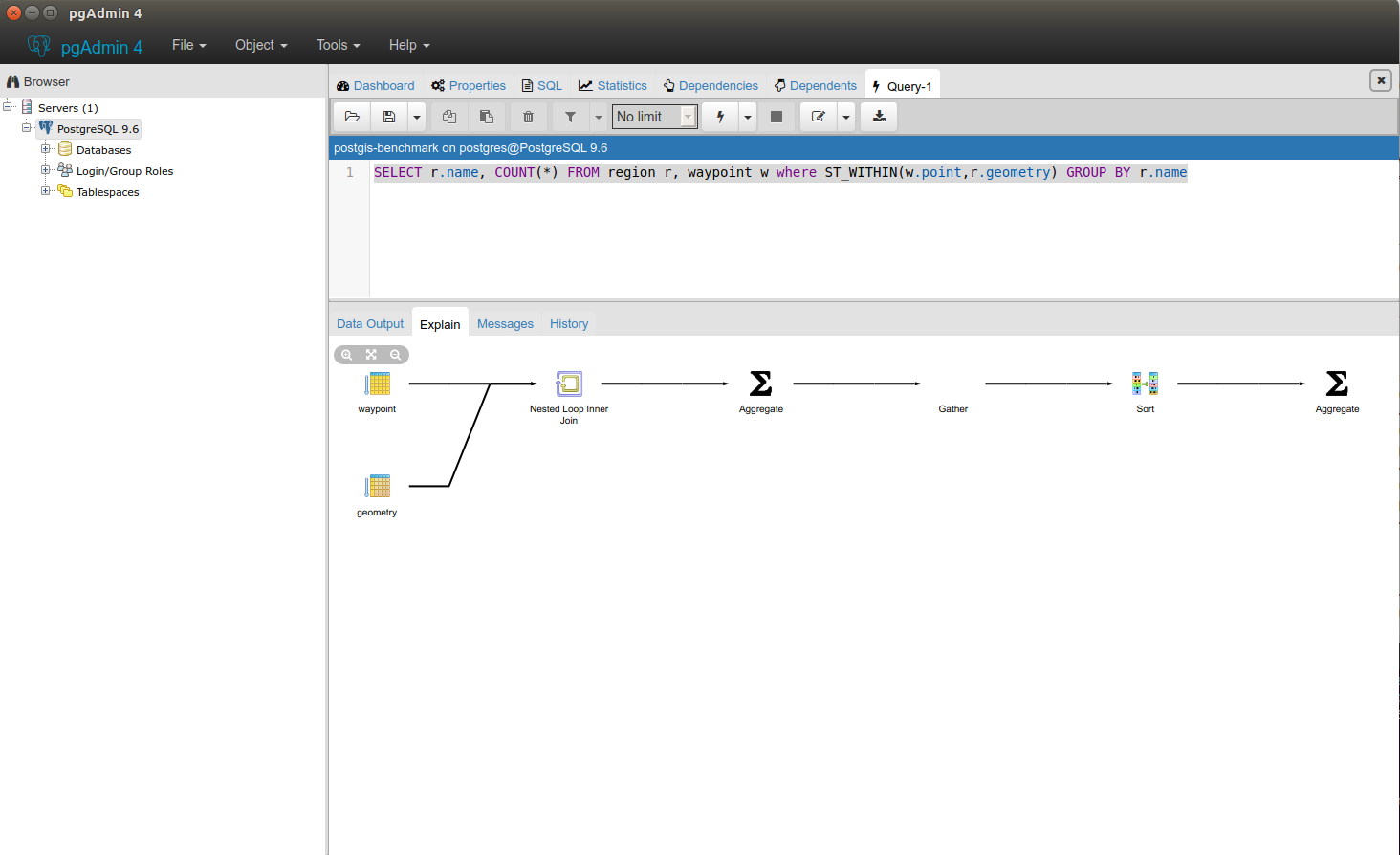
Here you can see the sequential query plan:
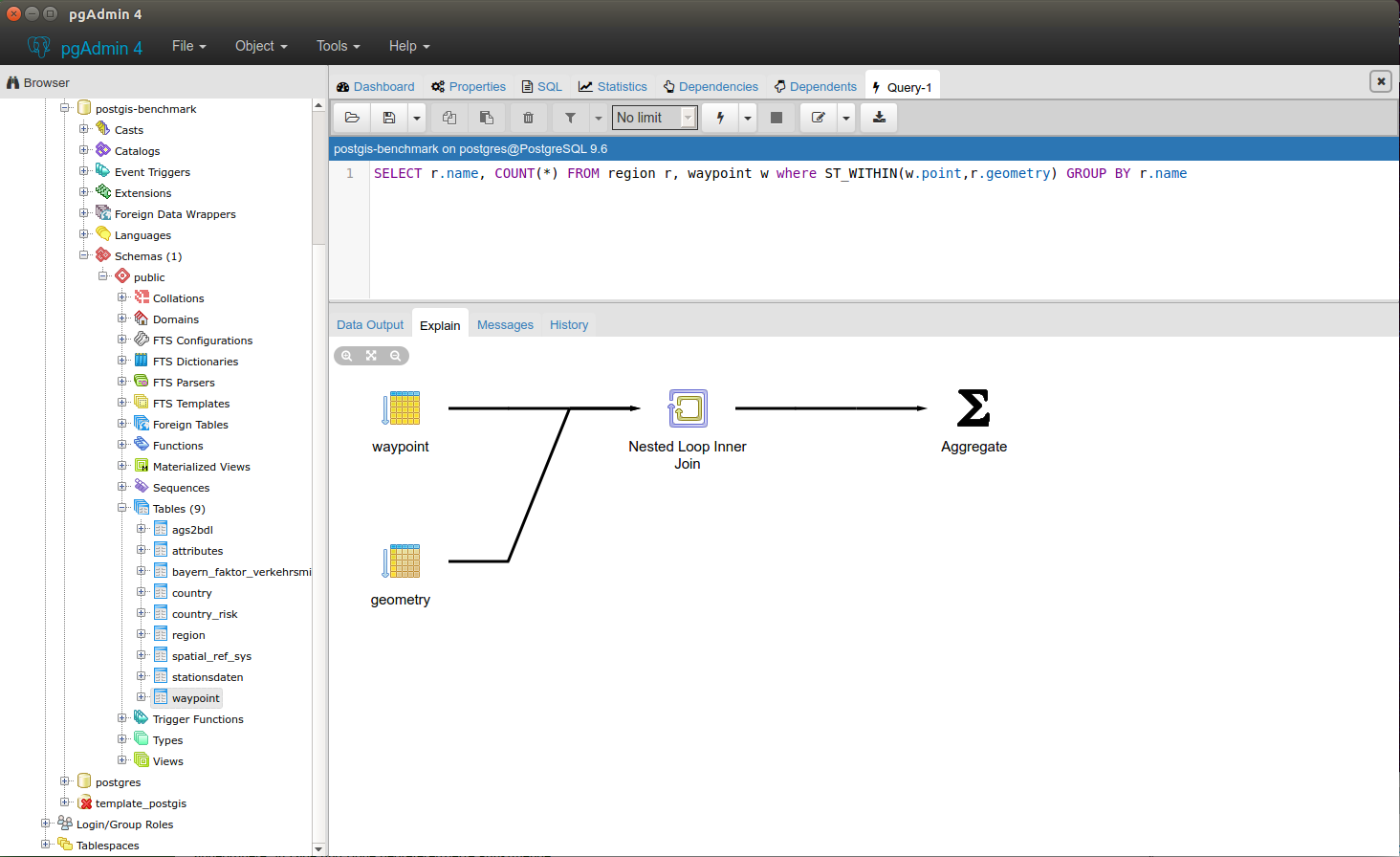

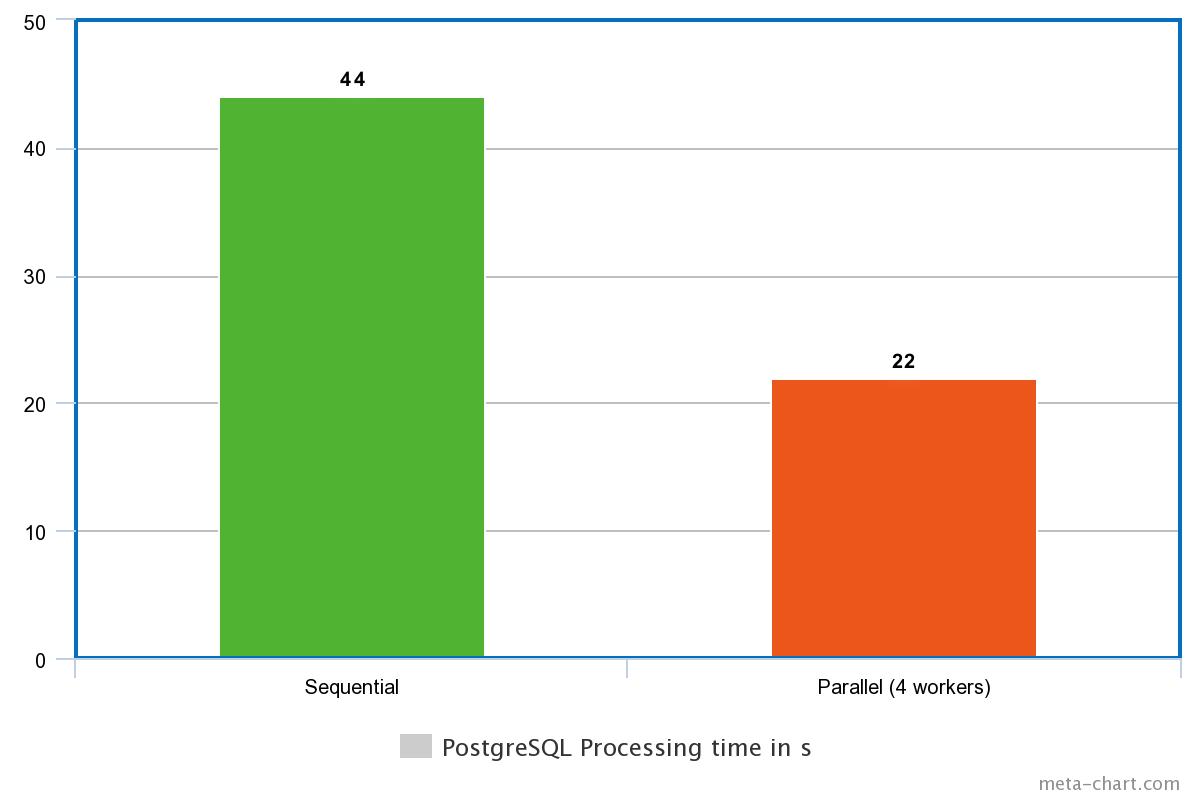
It takes 44s.
Then we set:
max_parallel_workers_per_gather =4
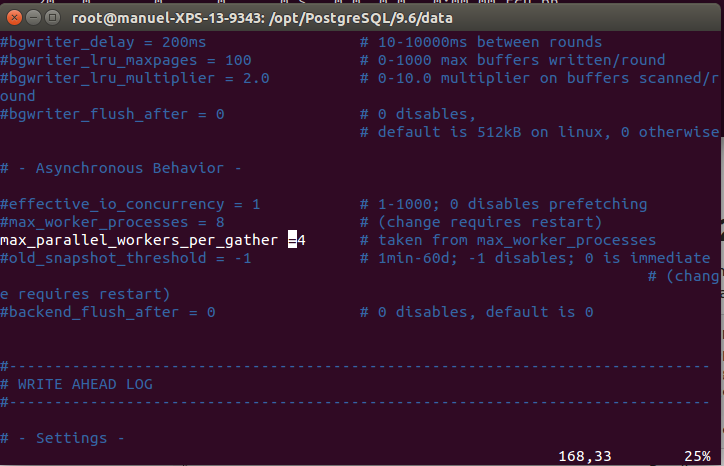
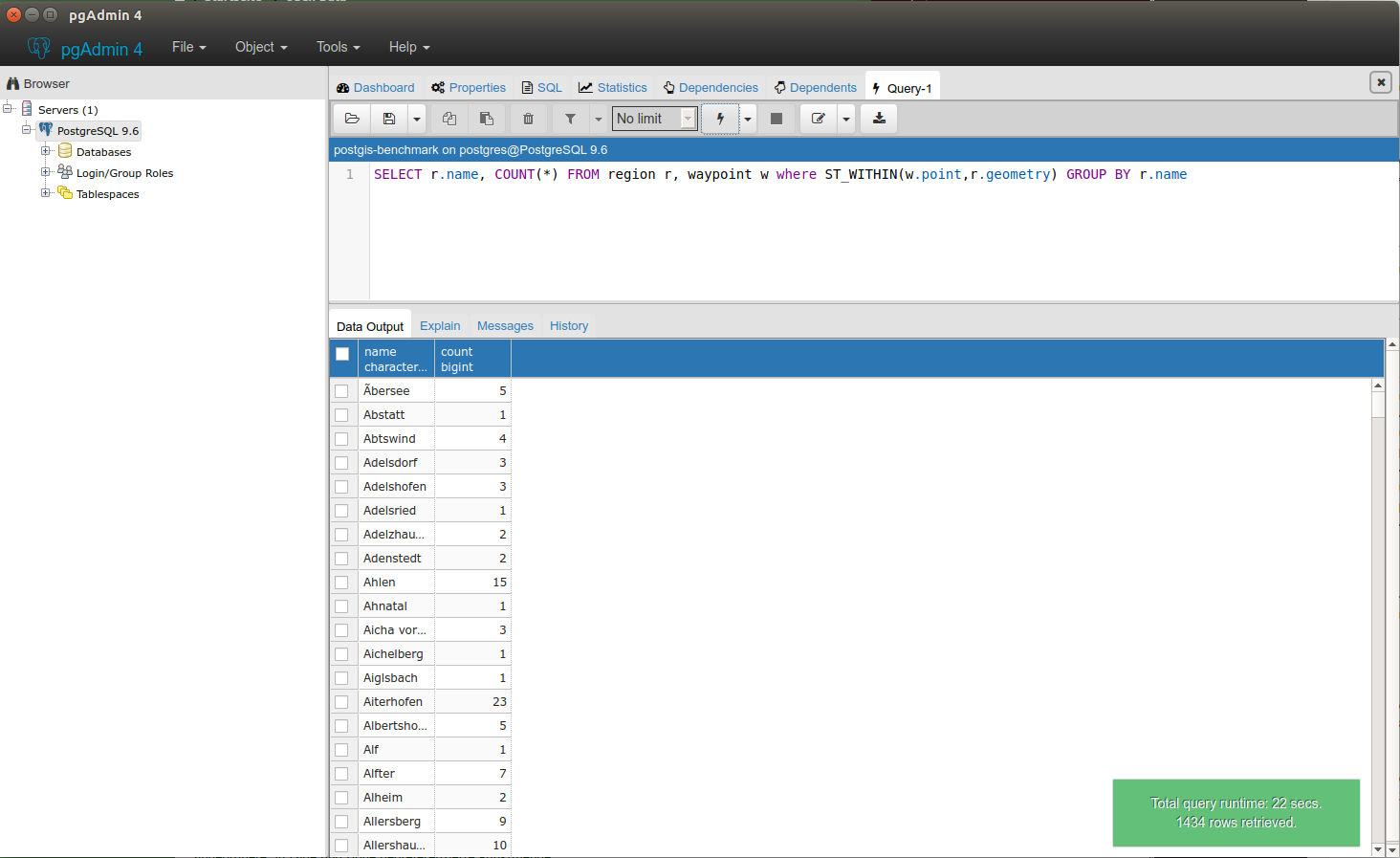
It takes 22s.
Hardware
- Dell XPS 13
- Intel Core i5-5200 CPU @ 2.20GHz x 4
- 8 GB Memory
- 256 GB SSD
Software
- Ubuntu Linux 14.04 LTS
- Linux manuel-XPS-13-9343 3.13.0-108-generic #155-Ubuntu SMP Wed Jan 11 16:58:52 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
- PostgreSQL 9.6.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.4.7 20120313 (Red Hat 4.4.7-16), 64-bit
- PostGIS 2.3.0 (64bit)
Conclusion
We can see that for this use case the speed is double as high.
Leave a Reply